Injection Is Not Influence: The Illusion of LLM Memory
After three years of building LLM applications, I've learned that LLM memory is fundamentally different from human memory.
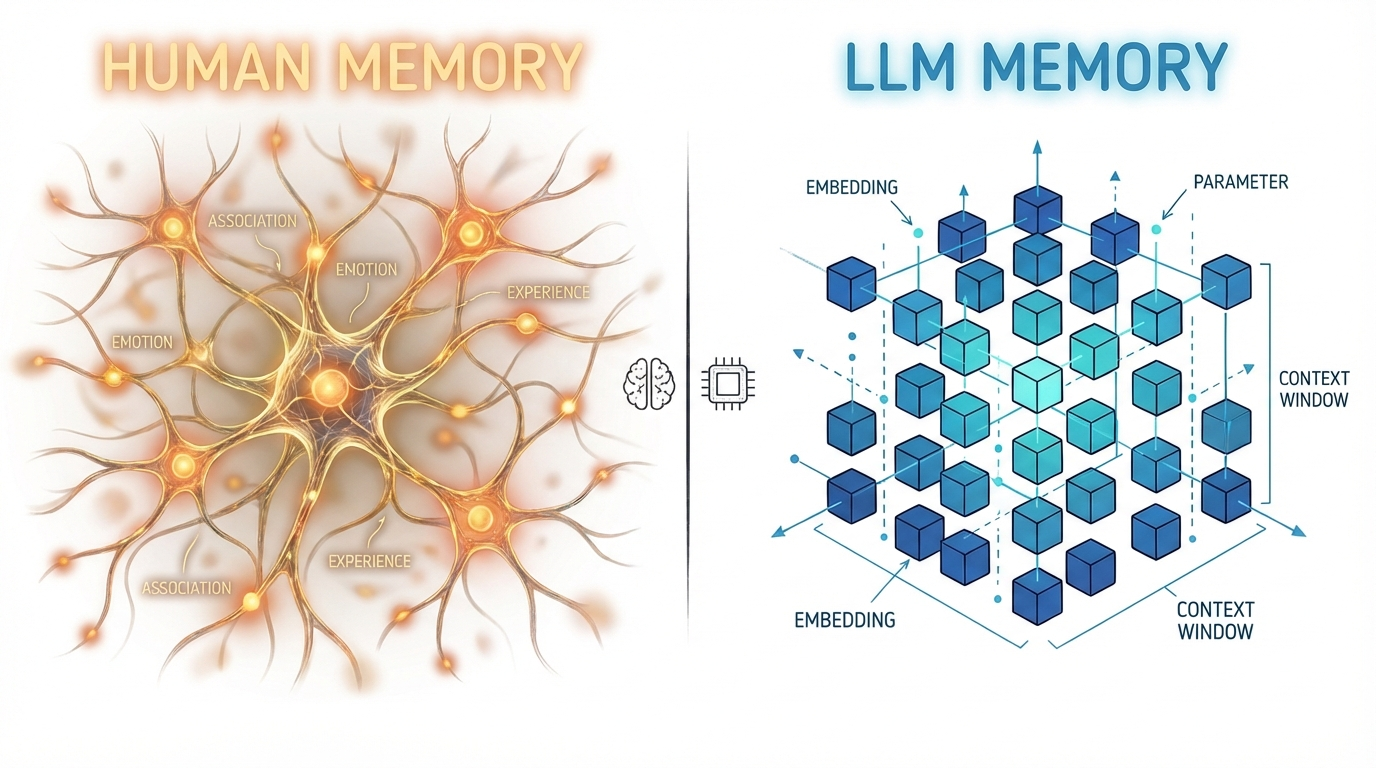
I've been building LLM applications for the last three years. Systems that don't just answer once and disappear, but talk, evolve, remember, and are expected to behave consistently over time.
And somewhere in that process, something became obvious to me: LLM memory is fundamentally different from human memory.
We keep using the same word — memory — but we're describing two very different mechanisms. That mismatch quietly shapes a lot of the problems we run into.
What We Mean When Humans "Remember"
When something reminds us of a past experience, we don't retrieve a compressed summary. We reconstruct a situation.
We remember the context. The constraints. What we tried. What failed. What worked. Sometimes tiny details that shouldn't matter logically, but somehow stayed.
Human memory preserves structure. It preserves causality.
Some memories fade. Some get reinforced. Some stay vivid for years. There is selectivity, depth, and gradual evolution. We don't consciously decide what to persist after every sentence. Memory strengthens through repetition, emotion, relevance, and time.
It's organic.
Memory and processing aren’t separate systems in humans. They’re intertwined. In LLM systems, they are explicitly decoupled.
What Real LLM Systems Actually Do
In production systems, memory is engineered.
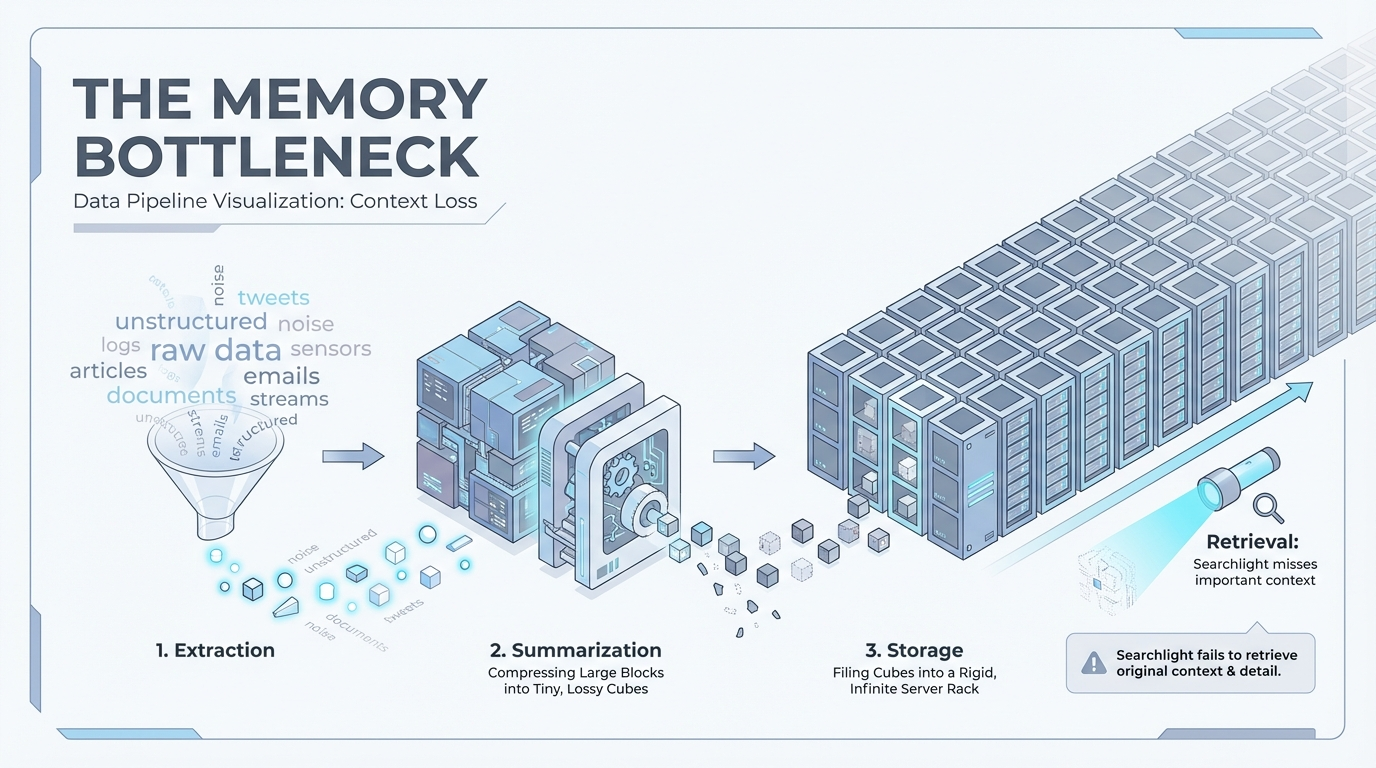
Typically, we do two things in parallel.
First, we extract useful information from individual user messages. Second, we periodically summarize longer conversations into something that can persist.
The per-message extraction is the "obvious" layer. If a user says something stable — their tech stack, their preference, their background — we try to capture it. This layer is often partially structured. Not fully rigid, because too much structure makes things brittle. But structured enough to be reusable later.
But here's the part that's easy to overlook: That extraction is done by an LLM.
Which means it is probabilistic.
We are asking a model, in real time:
- Is this a stable fact?
- Is this temporary?
- Is this preference or circumstance?
- Should this persist?
- How should it be represented?
And humans are vague. A user might say something ambiguous, half-formed, exploratory. The system has to interpret intent and permanence immediately.
- Sometimes it extracts things that shouldn't persist.
- Sometimes it misses things that matter later.
- Sometimes it stores something that becomes outdated but never reconciles it.
Then comes summarization. After long conversations, we compress what happened. We preserve the scenario and the outcome. But compression flattens reasoning paths. It keeps results and discards exploration.
So memory becomes a mix of:
- per-message extraction
- light structuring
- periodic summarization
And each layer depends on model judgment.
The fragility isn't just that summaries are lossy. It's that we've delegated persistence decisions to a probabilistic system operating on vague, shifting human input.
Humans don't make those decisions explicitly. Our memory evolves through use. LLM systems must decide instantly. That difference matters.
What I Used to Think
For a while, I thought the main bottleneck was multi-user architecture.
Traditional LLM systems are shared. The model is shared. The infrastructure is shared. Memory is external and partitioned per user. Humans don't work like that. Each person has their own processor tightly integrated with their own memory.
So I wondered: maybe memory feels weak because we're simulating something deeply personal on top of a shared, stateless engine.
If we had a true single-user LLM — one model continuously evolving with one individual — wouldn't memory feel more coherent?
There's some truth in that intuition. Systems optimized around one user often feel stronger. Retrieval is narrower. Noise is lower.
But even in a single-user setup, the hard problems don't disappear.
- You still have to decide what to store.
- You still have to interpret vague language.
- You still compress.
- You still retrieve based on imperfect signals.
The shared model makes scaling harder. It doesn't create the core tension.
The deeper issue is architectural.
LLMs are stateless processors. Memory is external.
Retrieval Is More Subtle Than It Looks
Even if extraction were perfect, retrieval introduces another layer of uncertainty.
Most systems rely heavily on embedding similarity. That works when two situations look similar on the surface. But humans retrieve based on structure, not just wording.
Two problems can use completely different vocabulary yet share the same underlying pattern. Humans recognize that pattern. Embedding similarity may not.
As memory grows, this tension increases.
- Store too much and retrieval becomes noisy.
- Store too little and continuity breaks.
- Compress too aggressively and you lose causality.
- Keep everything and the model starts ignoring the memory block.
There's no obvious equilibrium.
The Part We Rarely Measure
There's another uncomfortable layer to this.
Even when we retrieve memory and inject it into the prompt, we often don't know whether it was actually used.
Injection is not the same as influence.
We assume that because memory was present, it shaped the answer. But we rarely measure that explicitly. We rarely build feedback loops that tell us which memories were helpful and which were irrelevant.
So memory accumulates. Some entries remain useful. Some become stale. Some contradict newer facts. Some are repeatedly retrieved but never meaningfully influence responses.
Without observability, memory systems slowly degrade.
Not because the idea is wrong. But because nothing is reinforcing the useful parts and letting the rest fade. Humans reinforce memory through use. Systems rarely do.
Bigger Context Windows Won't Fix This
Increasing context size reduces how often we need to summarize or retrieve.
But it doesn't solve:
- Ambiguous extraction
- Lossy compression
- Structural mismatch in retrieval
- Lack of reinforcement
It just postpones the pressure. Eventually, you still have to decide what deserves persistence.
So What Is the Real Bottleneck?
After three years of building in this space, I don't think the main issue is that models forget.
The deeper problem is that we are asking probabilistic systems to make hard, irreversible decisions about persistence in the presence of vague human language — and then we rarely close the loop to see whether those decisions were useful.
Memory in LLM systems isn't about storing more tokens. It's about representing experience in a way that preserves structure over time.
It's about deciding what deserves to persist. It's about retrieving based on meaningful similarity, not just surface semantics. It's about reinforcement and decay.
And we are still early in figuring out what "remembering" should actually mean in machine systems. The moment we stop pretending that LLM memory is just a bigger context window, and start treating it as a design problem about persistence, structure, and feedback, the conversation changes.
We're not trying to copy the human brain. We're trying to define what remembering should look like for machines.
And that question is still wide open.